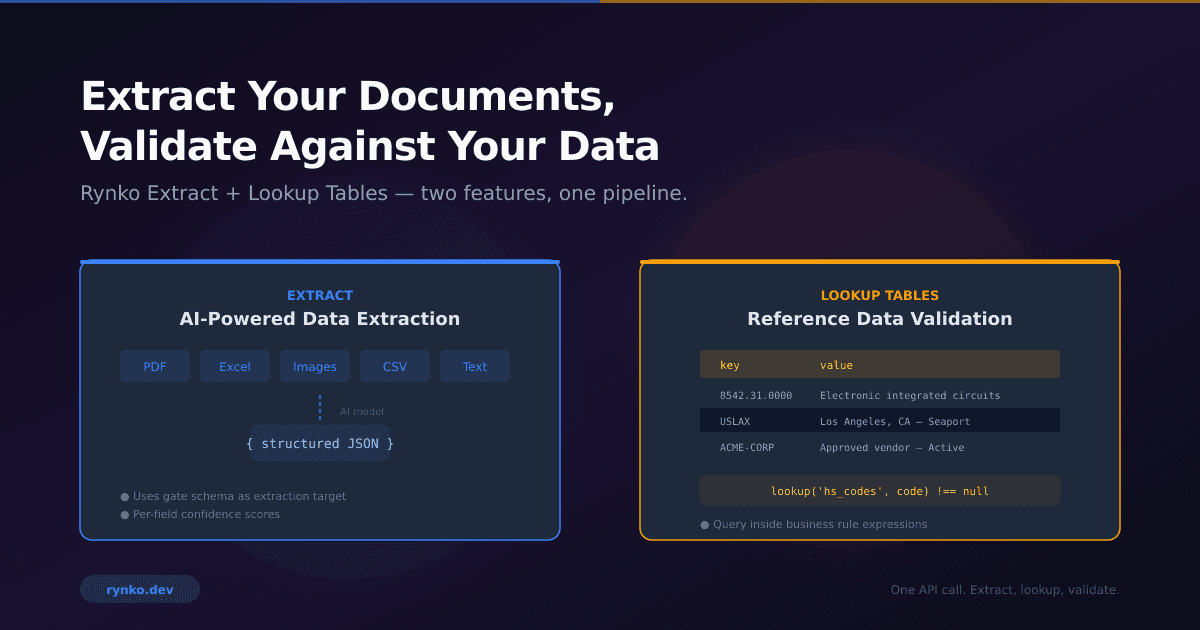
Extract Your Documents, Validate Against Your Data: Introducing Rynko Extract and Lookup Tables
An AI agent receives a trade document. It needs to extract the HS codes, verify them against the Harmonized Tariff Schedule, check the vendor against an approved list, and flag anything that doesn't match. Before today, that was three systems and a lot of glue code. Now it's one pipeline with one API call.
Until now, Rynko Flow assumed that agents would submit structured JSON for validation. And many do — when the data starts out structured. But a large number of real workflows start with a PDF, a scanned receipt, an Excel spreadsheet, or an email body that someone pasted into a form. The agent has the file, but not the data.
The typical workaround is to run the document through a separate OCR or extraction service, write glue code to map the extracted fields to your schema, handle the confidence issues, and then submit the result to your validation gate. And even after extraction, you often need to verify the extracted values against reference datasets — is this HS code valid? Is this vendor approved? Does this SKU exist in our catalog? That's another integration point, another system to maintain.
Today we're launching two features that solve both problems together: Rynko Extract and Lookup Tables.
Extract adds a Stage 0 to the Flow pipeline. Upload a file to a gate, and the AI extracts structured data from it before validation runs. Lookup Tables let you upload reference datasets — tariff codes, vendor lists, product catalogs — and query them directly inside your gate's business rules. Together, they turn a multi-system integration problem into a single pipeline call.
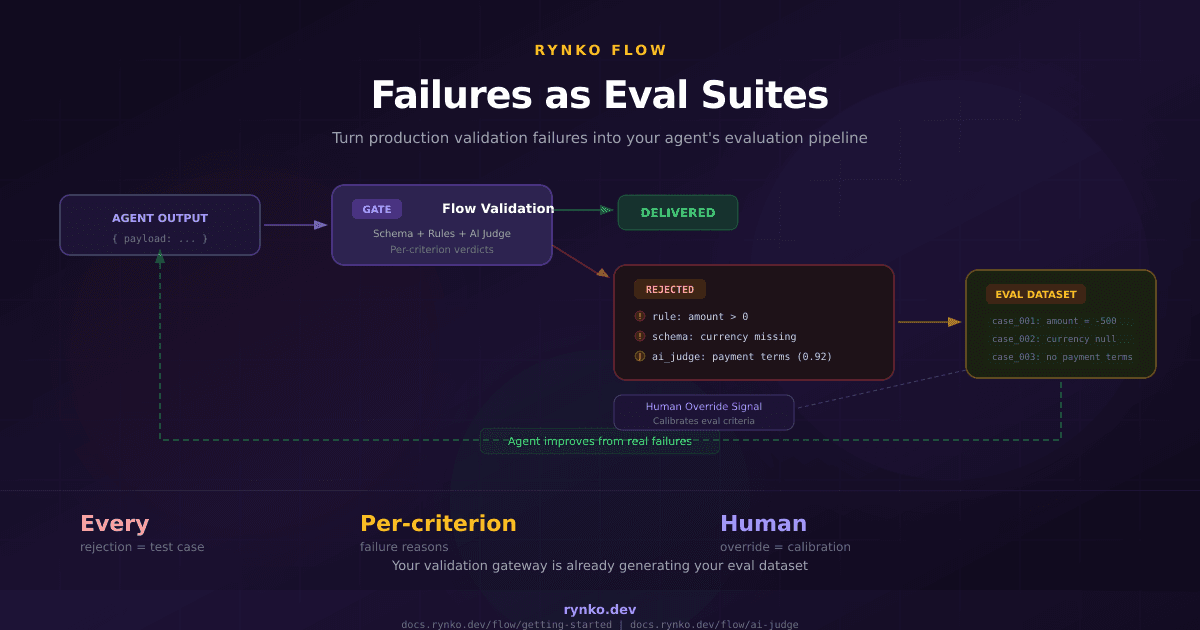
How Extract Works
When you enable Extract on a gate, the gate accepts both structured input (JSON, YAML, XML) and unstructured input (PDFs, images, Excel, CSV, plain text). Structured input skips extraction entirely — it goes straight to validation, no extraction credit consumed. Unstructured input passes through the AI extraction layer first, then the extracted data is validated against the gate's schema and business rules.
The key design decision was: one schema, not two. The gate's published schema serves as both the validation target and the extraction target. When the AI model extracts data from a document, it uses the gate's schema as a guide — field names, types, descriptions, required fields. There's no separate "extraction schema" to maintain. You edit the gate schema once, and both extraction and validation update together.

Per-Field Confidence Scoring
Every field that Extract returns comes with a confidence score — HIGH, MEDIUM, or LOW — along with a numerical score between 0 and 1. This isn't a binary "we found it or we didn't" signal. It tells you how reliable the extraction is for each individual field.
A clean invoice with a clearly printed invoice number in the header will get a HIGH confidence score of 0.95+. A handwritten note where the amount is partially obscured might get a LOW score of 0.3. The confidence scores are per-field, not per-document, so a single extraction can have high confidence on the vendor name but low confidence on the purchase order number.
We built three review modes around this. "Continue" accepts everything regardless of confidence — useful for high-volume, low-risk workflows. "Review" routes to a human reviewer when any field drops below your configured threshold or when required fields are missing. "Fail" rejects the extraction entirely if quality thresholds aren't met.
The review mode creates a human-in-the-loop workflow where the reviewer sees the extracted data alongside the source document, with confidence badges on each field. They can edit values, approve the extraction, or reject it. The edited data then continues through the validation pipeline — reviewer corrections are treated as the authoritative extraction result.
Schema Discovery and Zero-Cost Iteration
If you have a new document type and don't know what fields it contains, you can upload a sample file and let the AI analyze it. The AI returns a suggested JSON Schema with field names, types, and descriptions — a starting point you can refine.
The discovery pass stores the raw AI output as a "reference extraction" in S3. Every subsequent schema edit re-maps fields from this reference using a local field matcher — exact match, normalized match (snake_case to camelCase), description similarity, common aliases, and fuzzy matching. No AI calls, no credits consumed. You can iterate on your schema as many times as you want after the initial discovery, and the field matcher instantly shows you how the reference data maps to your updated schema.
This pattern — one AI call to establish the reference, then unlimited local iterations — makes it practical to experiment with schema design without worrying about API costs.
How Lookup Tables Work
A lookup table is a team-level key-value store. You create a table, populate it with entries (either one at a time via the API or in bulk via CSV/JSON upload), and then reference it in your gate's business rules using the lookup() function.
The simplest example is an existence check:
// Is this HS code in our tariff schedule?
lookup('hs_codes_us', hs_code) !== null
The lookup() function takes a table name and a key, and returns the stored value if the key exists, or null if it doesn't. Since values are stored as JSON, you can store rich objects and access their properties:
// Is this item restricted?
lookup('hs_codes_us', hs_code).restricted !== true
// Is the unit price within the expected range for this category?
lookup('price_ranges', product_category).max >= unit_price
// Composite key for duty rate lookup
lookup('duty_rates', hs_code + ':' + origin_country + ':' + destination_country) !== null
You can also use the fail() function for prescriptive error messages that tell agents exactly what went wrong:
lookup('vendors', vendor_name) !== null
? true
: fail('Vendor "' + vendor_name + '" not in approved list. Check spelling or onboard new vendor.')
This works well with Gate Intelligence — agents that fail a lookup check get a clear, actionable error message instead of a generic "rule failed" response.
The Double-Blind Principle
One design decision worth explaining: lookup table data is not sent to the AI during extraction.
This might seem counterintuitive — wouldn't extraction be more accurate if the model knew the valid HS codes? In practice, the opposite is true. If you give an LLM a list of 5,000 valid codes and ask it to extract an HS code from a blurry scan, it will "correct" what it sees to match something in the list. Instead of honest extraction, you get confident guessing.
We separate the roles deliberately. The AI is a witness — it reports exactly what it sees in the document, with a confidence score for each field. The gate is the judge — it checks the extracted values against your business rules and lookup tables deterministically. The lookup table is the law — it defines what's valid.
This means an extraction might come back with hs_code: "8471.30" at HIGH confidence, and then the gate rule lookup('hs_codes_us', hs_code) !== null confirms it's a real code. Or the extraction returns hs_code: "8471.39" (an OCR misread), the lookup fails, and the run routes to human review where the reviewer can see both the extracted value and the source document side by side.
The separation preserves the integrity of both steps. The extraction quality isn't artificially inflated by reference data matching, and the validation is fully deterministic — no probabilistic reasoning in the judgment step.
Atomic Bulk Sync
For small reference datasets — approved vendor lists, product categories — adding entries one at a time through the API is fine. But HS code databases have tens of thousands of entries, and product catalogs can have hundreds of thousands.
Bulk sync handles this with a shadow-flip pattern. When you upload a CSV or JSON file, the system writes all new entries at a new version number while your gate continues reading from the current version. Once all entries are imported, a single database update atomically switches the active version. There's no moment where your gate sees partial data — it's either the old complete dataset or the new complete dataset.
POST /api/flow/lookup-tables/:tableId/sync
Content-Type: multipart/form-data
file: hs_codes_2026.csv
mode: replace
The sync runs asynchronously via BullMQ, and you can poll the status or check the sync history. Each sync records how many entries were received, imported, and skipped, along with the duration.
Key Normalizers
One problem that came up immediately during testing: HS codes. Some invoices format them with dots (8542.31.0000), some without (8542310000). Both are the same code. A vendor extracted as ACME CORP won't match a lookup table entry stored as Acme Corp. Port codes might come through as uslax instead of USLAX.
Rather than forcing users to pre-process their data or write normalizing wrappers around every lookup() call, we added key normalizers at the table level. Each lookup table can specify a normalization strategy that's applied automatically — both when entries are stored and when keys are queried.

POST /api/flow/lookup-tables
{
"name": "hs_codes_us",
"keyNormalizer": "strip_dots",
"keyDescription": "10-digit HTS code",
...
}
With strip_dots, the expression lookup('hs_codes_us', '8542.31.0000') matches a stored key of 8542310000 because both are normalized to 8542310000 before comparison. The original key is preserved for display — you still see 8542.31.0000 in the UI — but matching uses the normalized form.
Seven normalizer types are available:
| Normalizer | Transformation | Use Case |
|---|---|---|
none |
No change (default) | Exact match |
lowercase |
Lowercase + trim | Vendor names, company names |
uppercase |
Uppercase + trim | Port codes, country codes |
strip_dots |
Remove dots + trim | HS codes |
strip_punctuation |
Remove dots, dashes, spaces + lowercase | Tax IDs (EIN, EORI) |
alphanumeric |
Keep only a-z 0-9 + lowercase | SKUs, part numbers |
numeric |
Keep only digits | Phone numbers, postal codes |
The normalization happens at write time — a normalizedKey column is pre-computed alongside the original key and indexed for O(1) lookups. This means even tables with millions of entries don't pay a performance penalty for normalization. Changing the normalizer on an existing table triggers a background recomputation of all normalized keys.
It's a small feature, but it eliminates an entire class of false validation failures that would otherwise require custom expressions or data cleansing pipelines.
The Pipeline Orchestrator
Behind both features is a pipeline orchestrator built as an independent package (@rynko/pipeline-core). It's a data-driven stage router — the pipeline is defined as an ordered array of stage definitions, and the orchestrator walks the array to determine what comes next. Adding a new stage to the pipeline is adding one entry to the array. Reordering stages is moving the entry.
The orchestrator is framework-agnostic — zero dependencies on NestJS, Prisma, or any specific infrastructure. It takes a storage adapter interface and a logger interface, and that's it. The Flow module provides a thin NestJS wrapper that implements the storage adapter using Prisma and wires the stage executors to the actual services.
The validation stage is special: for direct JSON submissions, it runs synchronously in the HTTP request handler with zero database operations — the response returns in single-digit milliseconds. Adding Extract to the pipeline doesn't slow down the existing validation path at all.
Lookup resolution is Redis-cached with lazy loading — only keys that are actually queried get cached, with a one-hour TTL. For gates that don't use lookup() in any rule, there's zero overhead. All lookups across all rules are resolved in a single batch before any rule evaluation begins — no I/O during rule execution.
The Full Pipeline
Here's what a complete pipeline looks like for trade document processing:
Extract (Stage 0): Agent uploads a commercial invoice PDF. The AI extracts vendor name, HS codes, line items, quantities, unit prices, total amount, origin country, destination country.
Validate (Stage 1): Gate rules check the extracted data:
Schema validation: required fields present, correct types
Business rules:
total_amount === sum of line item amountsLookup checks:
lookup('hs_codes_us', hs_code) !== nullfor every line itemLookup checks:
lookup('approved_vendors', vendor_name) !== nullLookup checks:
lookup('sanctioned_entities', vendor_name) === null(blocklist — must NOT be in table)
Review (if needed): Low-confidence extractions or failed lookup checks route to a human reviewer who sees the original document alongside the extracted data.
Deliver (Stage 2+): Validated data is delivered via webhook, or rendered into a standardized document via Rynko Render.
The entire flow is one API call from the agent's perspective. Upload a file, get back a run ID, poll for results. The agent doesn't need to know about extraction confidence scores, lookup table queries, or human review routing — the gate handles all of it.
What's Available
Extract and Lookup Tables are available now in founders preview. Extract comes with 100 free extraction credits per team. Lookup tables are included in your Flow tier, with limits scaling from 1 table and 1,000 entries on Free up to 25 tables and 10 million entries on Scale.
The extraction runs on Google Gemini 2.5 Flash for fast, cost-effective processing. SDK support covers Node.js, Python, and Java with submitFileRun() for gate pipeline integration. For agents that already have document content as text, text-based extraction is available via MCP tools. Lookup table management is available through the REST API, and the webapp UI for managing tables and entries is rolling out now.
If you're building agent workflows that start with documents and need to validate extracted data against reference datasets — tariff codes, approved vendor lists, product catalogs, sanctions lists — this is what we built it for. The docs are at docs.rynko.dev and we're at rynko.dev.