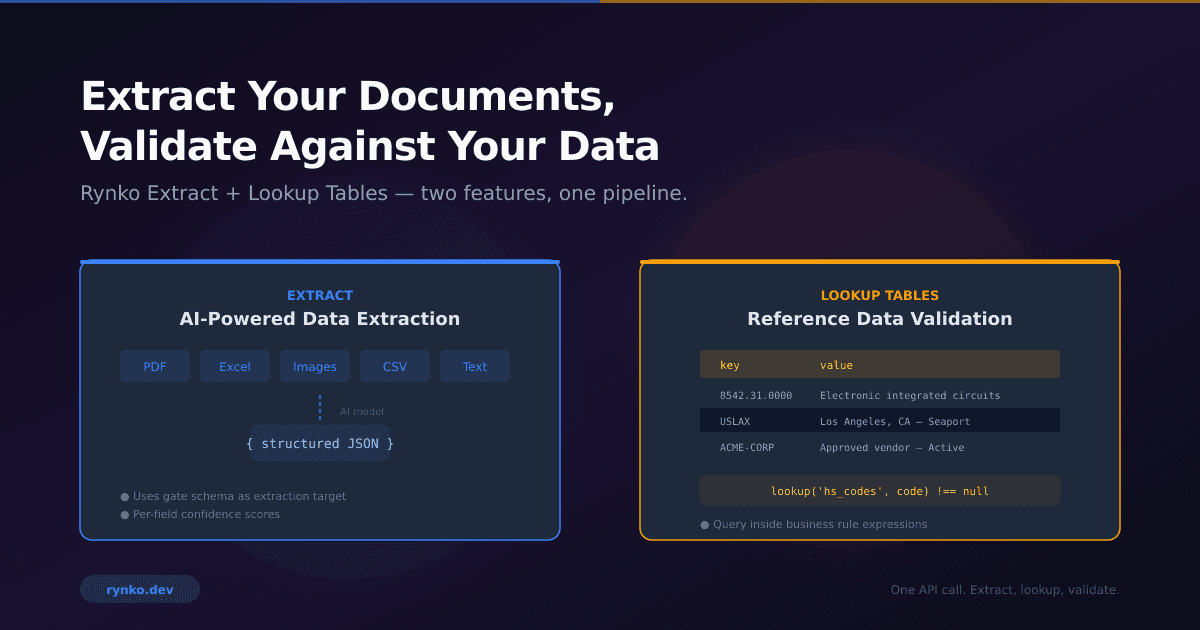
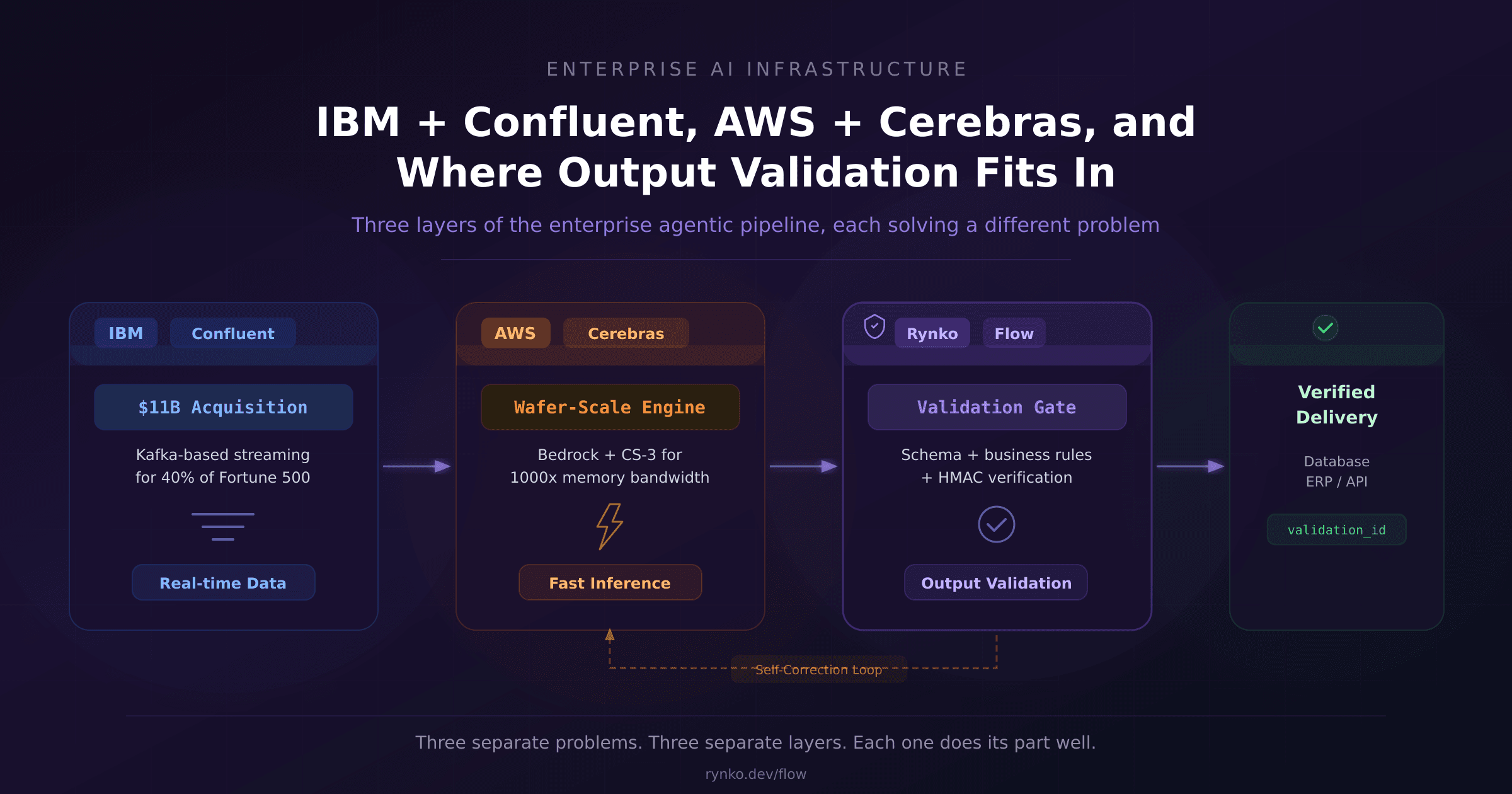
Madrigal's "Failures as Eval Suites" Pattern and How Flow Already Provides the Infrastructure
Madrigal Pharmaceuticals turned production failures into their evaluation pipeline. They built this custom on LangSmith. Flow gives you the same feedback loop as infrastructure.
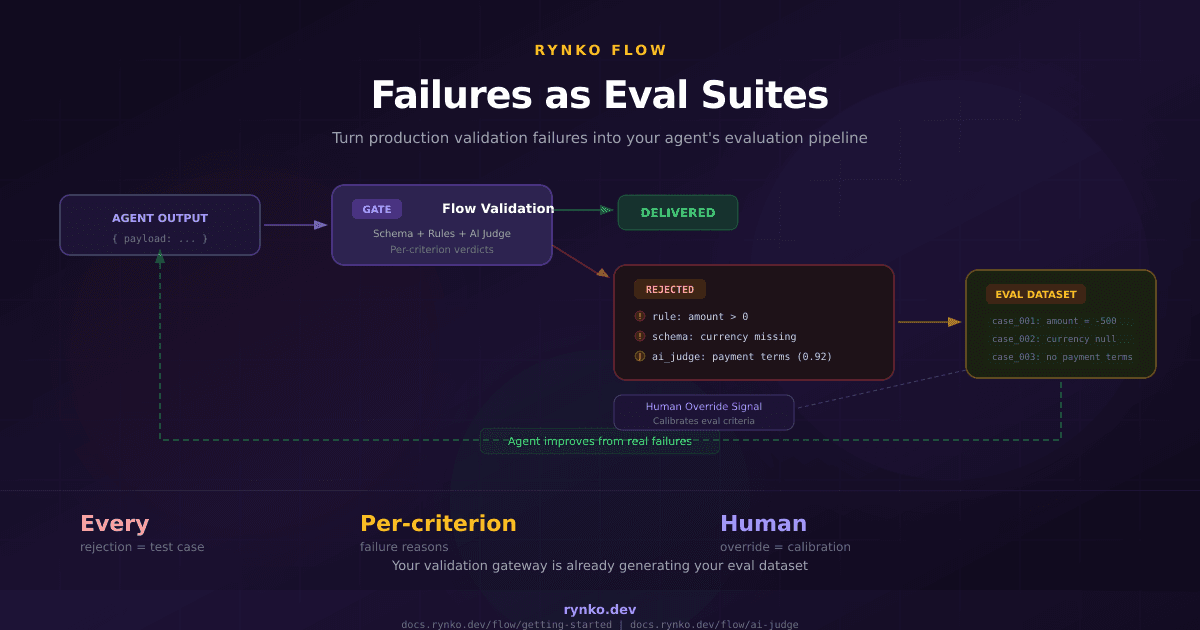
A blog post on LangChain's site about how Madrigal Pharmaceuticals built their multi-agent AI platform caught my attention this week. Not because of the architecture — orchestrator routing, parallel agents, shared workspace — that part is well-trodden ground by now. What stood out was one sentence buried in their quality assurance section:
"Production failures feed back into our LangSmith datasets automatically. Every meaningful error becomes a new test case. The eval suite grows from real failures, not synthetic scenarios."
This is the most underappreciated pattern in production AI right now: using your validation failures as your evaluation dataset.
Why Synthetic Evals Aren't Enough
Most teams building agent evaluation suites start the same way: write 50-100 synthetic test cases, run the agent against them, measure pass rates. It works for getting to v1. Then the agent goes to production, and you discover failure modes that none of your synthetic cases covered — because you couldn't have imagined them.
An invoice agent that passes every test but occasionally drops the currency field when the source data uses ISO 4217 codes it hasn't seen before. A contract extraction agent that handles English perfectly but silently returns empty arrays for bilingual documents. A code review agent that flags security issues correctly 98% of the time but gives a false positive on every string comparison that happens to contain "eval" in a variable name.
These are the failures that matter, and they only surface in production. Madrigal's insight was to capture them automatically and feed them back into their eval datasets. Their eval suite doesn't just test what they thought could go wrong — it tests what actually went wrong.
What Madrigal Built Custom
Madrigal's setup, based on the LangChain post, works roughly like this:
Agents process tasks in production
LangSmith traces every tool call, retrieval, and decision
When a meaningful error occurs, it's captured and added to a LangSmith dataset
That dataset becomes a test case for future agent iterations
LLM-as-judge evaluators grade full agent runs, using criteria that "mirror real end-user business feedback forms"
This is a solid approach, and LangSmith's tracing gives them visibility into the full chain of agent decisions. But there are two things worth noting about how they built it:
First, the evaluation is primarily LLM-based. They use "LLM-as-judge graders" that score outcomes. There's no mention of deterministic validation — schema checks, type enforcement, business rule evaluation — happening before the LLM judges the output.
Second, the failure capture appears to happen at the tracing level. When something goes wrong, the trace captures it. But traces capture everything — they don't inherently distinguish between "the agent made a wrong tool call" and "the agent's final output violated a business constraint." Both end up in the same dataset, and someone has to curate which failures are actually useful as eval cases.
Flow Already Captures This — With Structure
When we built Flow, we weren't thinking about it as an eval dataset generator. We built it as a validation gateway: agent submits output, Flow checks it against a schema and business rules, the output is either approved, rejected, or routed to a human. But it turns out that every rejected run is, by definition, a production failure case with structured metadata about what went wrong.
Here's what a Flow rejection looks like:
{
"success": false,
"status": "REJECTED",
"errors": [
{
"type": "business_rule",
"rule": "total === lineItems.reduce((sum, item) => sum + item.amount, 0)",
"message": "Line item amounts must sum to total",
"computed": { "total": 1250, "sum": 1150 }
},
{
"type": "schema",
"field": "currency",
"message": "Required field missing"
}
]
}
And when AI Judge is enabled, you also get:
{
"aiJudge": {
"criteria": [
{
"criterion": "Invoice must include a payment terms clause",
"verdict": "fail",
"confidence": 0.92,
"reasoning": "No payment terms found in the document. Net-30/60/90 clause is missing."
},
{
"criterion": "All monetary values must use two decimal places",
"verdict": "pass",
"confidence": 0.97,
"reasoning": "All amounts use consistent two-decimal formatting."
}
]
}
}
Every rejection tells you exactly which rules failed, what the computed values were, and (with AI Judge) which qualitative criteria the output didn't meet. That's not a raw error log — it's a structured eval case with a grading rubric attached.
Three Things Flow Captures That Traces Don't
1. Deterministic failure reasons before LLM evaluation
Madrigal's LLM-as-judge runs on every output. Flow's business rules catch schema violations and constraint failures before AI Judge even fires. If your agent submitted amount: -500, you don't need an LLM to tell you that's wrong — you need a rule that says amount > 0. The deterministic layer filters out failures that are unambiguous, so your eval dataset isn't polluted with cases where the answer is obvious.
2. Per-criterion failure granularity
When a Flow run fails AI Judge, you don't just get "the output was bad." You get per-criterion verdicts — which specific criteria failed, with what confidence, and why. If your agent keeps failing the "payment terms clause" criterion but passing everything else, that's a specific, actionable signal. You know exactly what to fix in your prompt or retrieval pipeline.
3. Human override signal
When a run goes to REVIEW_REQUIRED and a human approver overrides the AI's verdict — either accepting something the AI rejected or rejecting something the AI approved — that's a calibration signal for your eval criteria. If humans are consistently overriding a specific AI Judge criterion, the criterion is probably wrong or too strict. This is eval metadata you can't get from traces alone.
The Feedback Loop
Here's how the feedback loop works in practice:
The gate doesn't just validate — it generates the data that makes your agent better over time. Every failure is a test case. Every human override is a calibration signal. The eval suite grows from production reality, not from what you guessed might go wrong.
And because the rejection data is structured JSON with specific rule IDs, field names, and computed values, you can aggregate failure patterns across thousands of runs. "This agent fails the amount > 0 rule 3% of the time" is something you can track on a dashboard and watch improve over sprint cycles.
What We're Building Next
Reading the Madrigal post pushed us to think about this more explicitly. Right now, all the rejection data exists in Flow's run history — you can query it via the API, see it in the dashboard, and build reports on it. But we haven't made it easy to export that data into external eval platforms.
Here's what's on the roadmap:
Failure pattern dashboard. Group rejected runs by which rules and criteria failed most often. Instead of scrolling through individual runs, see at a glance that 40% of your rejections are the same missing field.
Eval dataset export. One-click export of rejected runs (with payloads, failure reasons, and human override data) in formats that work with eval tools — LangSmith datasets, Braintrust, or plain JSONL for custom pipelines.
Webhook on rejection. Fire a webhook when a run is rejected, with the full failure payload. Pipe it directly into your CI, your eval pipeline, or a Slack channel where your agent developers see it in real time.
Gate-level eval metrics. Track how your failure rate changes over time for each gate. When you push a new agent version, see whether the rejection rate went up or down — not just whether your synthetic eval suite passed.
How This Complements LangSmith
I want to be clear: this isn't a "Flow vs. LangSmith" argument. LangSmith does tracing, observability, and eval orchestration — it gives you visibility into what the agent did and why. Flow does output validation — it gives you a verdict on whether the agent's final output meets your requirements. They solve different problems, and using both makes the feedback loop stronger.
The ideal setup looks like this: LangSmith traces the agent's reasoning chain. Flow validates the agent's output. When Flow rejects a run, that rejection — with its structured failure reasons — gets added to a LangSmith dataset. Now your eval suite tests both the reasoning (via traces) and the output quality (via Flow's validation criteria). The agent gets better at both thinking and producing.
Madrigal built the output validation part custom. If they'd had Flow, they could've defined their validation criteria as gates and gotten structured rejection data for free, instead of parsing it out of traces.
Getting Started
If you're running agents in production and want to start building an eval suite from real failures:
Define a Flow gate with the schema and business rules your agent's output needs to satisfy
Add AI Judge criteria for the qualitative checks you can't express as rules
Point your agent at the gate — one API call per submission
Pull rejected runs from the API and add them to your eval dataset
Watch your rejection rate decrease as your agent improves
The free tier gives you 500 runs per month and three gates. Enough to validate whether this pattern works for your pipeline before committing to it.
Rynko Flow is a validation gateway for AI agent outputs. Try it free or read the docs.