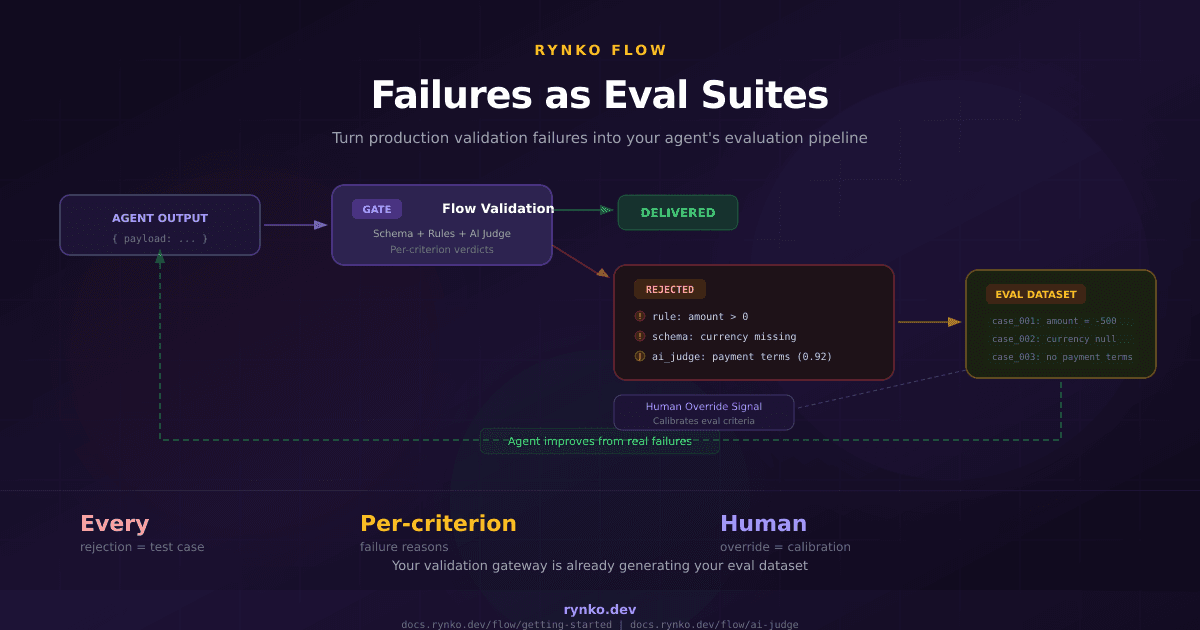
Design Once, Generate Anywhere: How Our Unified Template System Works
One template. Two formats. Zero compromise. Here's how Rynko generates both PDF and Excel from a single template design.
Most document generation tools make you choose: build a PDF template or an Excel template. Need both formats? Build two templates, maintain two schemas, handle two sets of bugs.
We thought that was unnecessary. So, we built a unified template system where you design once and generate in any format. This post explains how it works under the hood.
The Problem with Separate Templates
Consider a typical invoice. Your sales team wants PDF invoices for customers. Your finance team wants the same data as Excel for their accounting software. Your ops team wants Excel reports they can sort and filter.
With traditional tools, you'd maintain:
An HTML template for the PDF invoice
A separate Excel template (or code that builds spreadsheets)
Logic to keep both templates in sync when the invoice format changes
When someone adds a "discount" field, you update the PDF template, then remember to update the Excel template too. Inevitably, they drift apart.
The Rynko Approach
In Rynko, a template is a JSON document that describes the structure and data of your document, not the final visual output. The renderers — one for PDF, one for Excel — interpret that structure for their respective formats.
Here's a simplified view of an invoice template:
{
"name": "Invoice",
"format": "both",
"variables": [
{ "name": "invoiceNumber", "type": "string" },
{ "name": "customerName", "type": "string" },
{ "name": "items", "type": "array", "itemType": "object",
"schema": {
"itemSchema": {
"properties": {
"description": { "type": "string" },
"quantity": { "type": "number" },
"price": { "type": "number" }
}
}
}
},
{ "name": "total", "type": "number" }
],
"sections": [
{
"components": [
{ "type": "heading", "props": { "text": "Invoice #{{invoiceNumber}}" } },
{ "type": "text", "props": { "text": "Bill to: {{customerName}}" } },
{
"type": "dataTable",
"props": {
"dataSource": "{{items}}",
"columns": [
{ "header": "Description", "field": "description" },
{ "header": "Qty", "field": "quantity" },
{ "header": "Price", "field": "price", "format": "currency" }
]
}
},
{ "type": "text", "props": { "text": "Total: ${{total}}", "bold": true } }
]
}
]
}
This single template produces both a formatted PDF and a structured Excel workbook. The same variable data feeds both.

How the Rendering Works
The Layout Engine: Yoga
At the core of our PDF and Designer pipeline is Yoga — the same flexbox layout engine that powers React Native. Every component in a template becomes a Yoga node with flex properties:
Template Section
├── Heading node (flex: row, alignItems: center)
├── Text node (marginBottom: 10)
├── DataTable node
│ ├── Header row (flex: row, backgroundColor: #f5f5f5)
│ └── Data rows (flex: row, borderBottom: 1px)
└── Total text node (flex: row, justifyContent: flex-end)
Yoga calculates the exact position and size of every element. This gives us pixel-perfect PDF layout and live preview in the designer — without parsing HTML or running a browser.
For Excel, we bypass the pixel layout engine entirely and map the component tree directly to spreadsheet rows and columns. Yoga deals in X/Y coordinates; Excel deals in rows and cells — so each renderer interprets the same component tree in the way that's native to its format.

PDF Renderer
The PDF renderer takes the Yoga layout tree and draws directly to PDFKit:
Layout pass: Yoga calculates positions for all nodes
Render pass: Each component type has a renderer that draws to PDFKit
heading→doc.fontSize(24).text(...)dataTable→ Table drawn with lines, cells, formattingimage→doc.image(...)with proper scalingchart→ Rendered to canvas, then embedded as image
Pagination: When content exceeds page height, automatic page breaks with header/footer repetition
Output: Native PDF file, no browser involved
Result: 200-500ms generation, ~50MB memory.

Excel Renderer
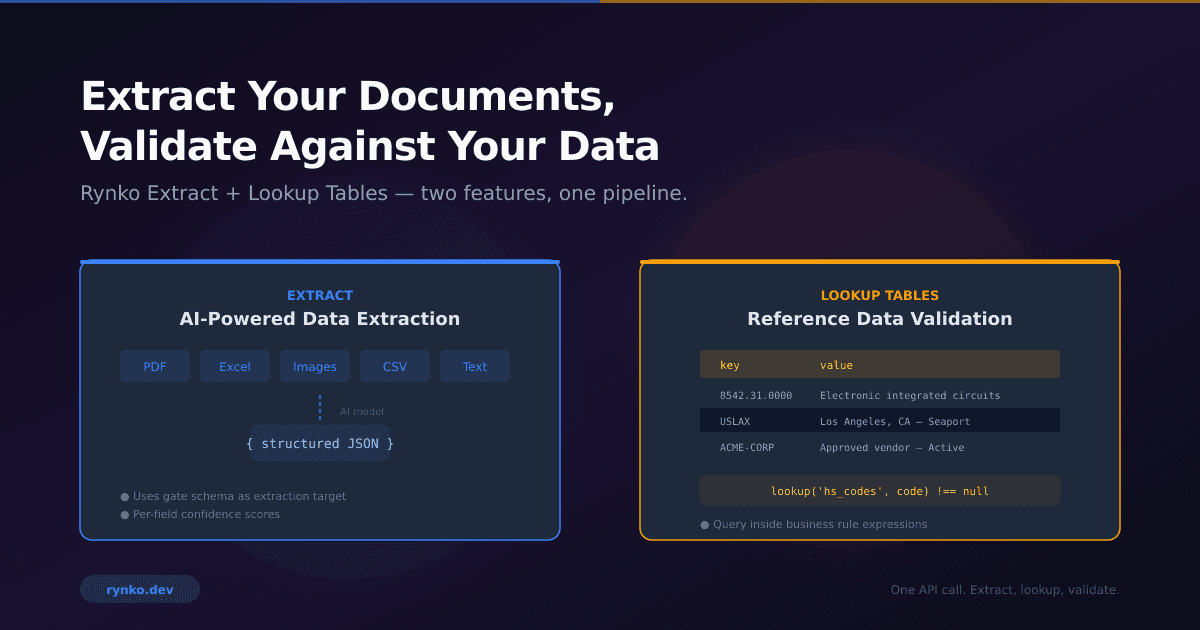
The Excel renderer interprets the same template for spreadsheet format:
Sheet mapping: Each template section can map to an Excel sheet
Component translation:
heading→ Merged cells with bold formattingtext→ Cell with text and formattingdataTable→ Excel table with headers, data rows, and auto-filterschart→ Native Excel chart objectimage→ Embedded image in cell
Formula support: Define native Excel formulas in your template for cells that should calculate in the spreadsheet
Formatting: Fonts, colors, borders, number formats translate to Excel styles
Result: A proper .xlsx file with native Excel features — not a CSV, not a screenshot of a table.
Component-by-Component Translation
All 28 component types and how they map across formats:
Content Components
| Component | PDF Rendering | Excel Rendering |
| Text | Positioned text with font styling | Cell with formatted text |
| Rich Text | Multiple styles per line (bold, italic, links) | Rich text cell with formatting runs |
| Heading | Large text with configurable level (h1-h6) | Merged cells with bold/large font |
| Title | Large heading variant with emphasis | Merged cells with prominent styling |
| Image | Embedded image with scaling | Embedded image anchored to cell |
| List | Bulleted/numbered list items | Rows with indent and bullet/number prefix |
| Divider | Horizontal line (solid/dashed/dotted) | Bottom border on cells |
| Spacer | Empty space with configurable height | Empty row(s) |
| SVG | Rendered as embedded image | Rendered as embedded image |
| QR Code | Rendered as embedded image | Rendered as embedded image |
| Barcode | Rendered as embedded image (10 formats) | Rendered as embedded image |
Layout Components
| Component | PDF Rendering | Excel Rendering |
| Container | Wrapper with background, border, padding | Styled cell region |
| Columns | Flex layout side-by-side | Adjacent cells |
| Table Layout | Grid with cell positioning and spans | Cells with colspan/rowspan |
| Conditional | Show/hide based on expression | Show/hide based on expression |
| Loop | Repeated section for each array item | Repeated rows for each array item |
| Page Break | New PDF page | New Excel sheet or row separator |
Data & Visualization Components
| Component | PDF Rendering | Excel Rendering |
| Table | Drawn table with borders and styling | Native Excel table with auto-filters |
| Chart | Rendered as embedded image (8 chart types) | Native Excel chart object |
| Key-Value | Label-value pairs with layout options | Two-column cell pairs |
| Formula | N/A | Native Excel formula cell (=SUM(...)) |
PDF Form Components (PDF only)
| Component | PDF Rendering |
| Form Text | Single-line text input field |
| Form Textarea | Multi-line text input |
| Form Checkbox | Boolean checkbox with label |
| Form Radio | Radio button group with options |
| Form Dropdown | Select dropdown with options |
| Form Date | Date picker with format configuration |
| Form Signature | Signature placeholder (text, image, or digital) |
| Form Button | Interactive button (print, reset, link) |
What's Format-Specific
Some features only make sense in one format:
PDF only:
8 fillable form field types (text, textarea, checkbox, radio, dropdown, date, signature, button)
Custom fonts
Precise Yoga flexbox positioning
Page headers and footers
Excel only:
Native Excel formulas via Formula component
Auto-filters on data tables
Sortable columns
Cell-level data types (dates as dates, numbers as numbers)
The Variable System
Variables are format-agnostic. You define them once, and both renderers use the same data:
Scalar Variables
{ "name": "customerName", "type": "string", "defaultValue": "John Doe" }
Works identically in both formats — the value appears wherever {{customerName}} is used.
Array Variables (Dynamic Tables)
{
"name": "items",
"type": "array",
"itemType": "object",
"schema": {
"itemSchema": {
"properties": {
"description": { "type": "string" },
"quantity": { "type": "number" },
"price": { "type": "number" }
}
}
}
}
PDF: Renders as a table with one row per array item, automatically paginating
Excel: Creates data rows with proper column types and formatting
Calculated Variables
{ "name": "subtotal", "type": "number", "expression": "items.reduce((sum, item) => sum + item.quantity * item.price, 0)" }
PDF: Evaluated server-side, result rendered as text
Excel: Evaluated server-side, result placed in the cell as a static value. If you need live Excel formulas (e.g.,
=SUM(D2:D10)), define them separately in the template's Excel formula configuration
System Variables
Both formats support system-provided variables like __CURRENT_DATE__, __COMPANY_NAME__, __TEMPLATE_NAME__, etc. These are resolved identically regardless of output format.
Why This Architecture?
We considered several approaches before settling on the Yoga-based unified template:
Rejected: HTML as the Source
We could have used HTML templates and converted to both PDF and Excel. But:
HTML-to-Excel conversion is lossy — you can't preserve semantic data
Tables in HTML become images or flat text in Excel, losing sort/filter capability
Browser-based rendering is slow and resource-heavy
Rejected: Separate Templates with Shared Schema
We could have had separate PDF and Excel templates that share the same variables. But:
Two templates to maintain = two places for bugs
Templates inevitably drift apart
More work for template designers
Chosen: Abstract Component Tree
By defining templates as an abstract component tree (not HTML, not Excel XML), each renderer can interpret components optimally for its format:
The PDF renderer uses Yoga for precise layout
The Excel renderer uses native Excel features (real tables, real formulas)
Both consume the same template and variables
Try It Yourself
You can see this in action in under 5 minutes:
Sign up free at Rynko
Create a template in the visual designer
Click "Preview" and toggle between PDF and Excel output
Send the same data via API and get both formats
Here's the dual-format payoff in code — same template, same variables, two API calls:
import { Rynko } from '@rynko/sdk';
const rynko = new Rynko({ apiKey: process.env.RYNKO_API_KEY! });
const invoiceData = {
templateId: 'invoice',
variables: {
invoiceNumber: 'INV-2026-001',
customerName: 'Acme Corp',
items: [
{ description: 'Consulting', quantity: 10, price: 150.00 },
{ description: 'Software License', quantity: 5, price: 99.00 },
],
total: 1995.00,
},
};
// PDF for the customer
const pdf = await rynko.documents.generatePdf(invoiceData);
// Excel for the finance team — same template, same data
const excel = await rynko.documents.generateExcel(invoiceData);
Or, if you're using Claude or Cursor, ask the AI to create a template and generate both formats:
Create an invoice template, then generate it as both PDF and Excel
with sample data for 3 line items
The same JSON data, the same template, two perfectly formatted documents.
New to Rynko? Follow our Getting Started in 5 Minutes guide. Evaluating alternatives? See the PDF Generation API Comparison.
Get Started Free | Template Schema Reference | Rendering Engine
Questions about the rendering architecture? Join our Discord or check the engine page for the full breakdown.
Disclosure: I ideate and draft content, then refine it with the aid of artificial intelligence tools like Claude and revise it to reflect my intended message.